 ES - 高级查询操作
ES - 高级查询操作
# SearchAPI
ES支持两种基本方式检索;
- 通过REST request uri 发送搜索参数 (uri +检索参数);
- 通过REST request body 来发送它们(uri+请求体);
检索信息
检索从_search开始
例如:
GET bank/_search?q=*&sort=account_number:asc1等价于
GET bank/_search { "query":{ "match_all":{ } }, "sort":[ { "account_number":{ "order":"desc" } } ] }1
2
3
4
5
6
7
8
9
10
11
12
13响应结果解释: took - Elasticsearch 执行搜索的时间(毫秒) time_out - 告诉我们搜索是否超时 _shards - 告诉我们多少个分片被搜索了,以及统计了成功/失败的搜索分片 hits - 搜索结果 hits.total - 搜索结果 hits.hits - 实际的搜索结果数组(默认为前 10 的文档) sort - 结果的排序 key(键)(没有则按 score 排序) score 和 max_score –相关性得分和最高得分(全文检索用)
# 查询数据Query DSL
# 指定字段查询 match
查询 name 中含有 坤 或 小 的
GET /stars/_search
{
"query": {
"match": {
"name": "坤 小"
}
}
}
2
3
4
5
6
7
8
# 查询短语匹配 match_phrase
如果我们希望查询的条件是某字段中包含 "坤 小"
也就是将需要匹配的值当成一个整体单词(不分词)进行检索,使用 match_phrase
GET /stars/_search
{
"query": {
"match_phrase": {
"name": "坤 小"
}
}
}
2
3
4
5
6
7
8
# 多字段匹配 multi_match
查询 state 或者 address 包含 mill
GET bank/_search
{
"query":{
"multi_match":{
"query":"mill",
"fields":[
"state",
"address"
]
}
}
}
2
3
4
5
6
7
8
9
10
11
12
# 查询结果显示指定字段
例如,查询结果只显示 age 和 desc
GET /stars/_search
{
"query": {
"match": {
"name": "凡"
}
},
"_source":["age", "desc"]
}
2
3
4
5
6
7
8
9
# 排序和分页
- asc 升序、desc 降序
GET /stars/_search
{
"query": { "match_all": {} },
"sort": [
{
"age.keyword": {
"order": "desc"
}
}
]
}
2
3
4
5
6
7
8
9
10
11
- 分页查询
本质上就是 from(开始位置)和 size(返回数据数目)两个字段
GET /stars/_search
{
"query": { "match_all": {} },
"from": 0,
"size": 2
}
2
3
4
5
6
# 多条件查询
- bool
must:相当于关系型数据库 and
GET stars/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "吴亦凡"
}
},
{
"match": {
"age": "29"
}
}
]
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
should:相当于关系型数据库 or
GET stars/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"name": "吴亦凡"
}
},
{
"match": {
"age": "19"
}
}
]
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
must_not:相当于关系型数据库 not
# 结果过滤查询 filter
例如,查询 10岁<=age=<30岁
GET stars/_search
{
"query": {
"bool": {
"filter": [
{
"range": {
"age": {
"gte": 10,
"lte": 30
}
}
}
]
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 匹配多个条件查询
查询 tags 有 唱跳 的
GET stars/_search
{
"query": {
"match": {
"tags": "唱 跳"
}
}
}
2
3
4
5
6
7
8
多个条件使用空格隔开
# 精确查询term
关于分词
- term:直接通过倒排索引指定的词条进行精确查询
GET stars/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"name": "吴亦凡"
}
}
]
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
返回
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
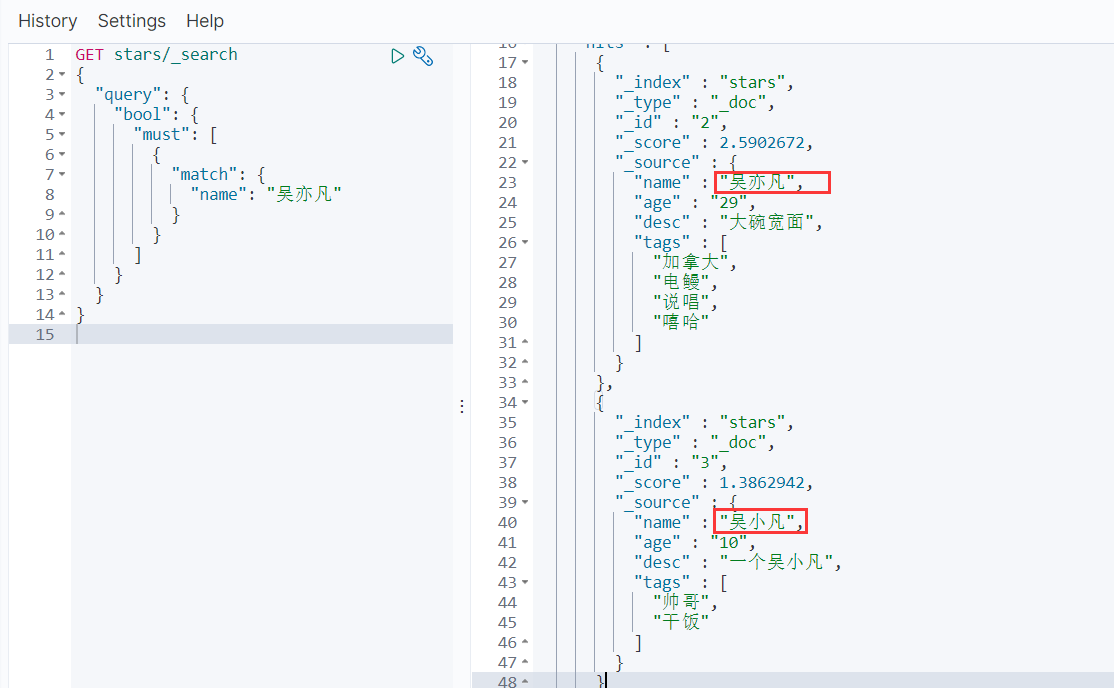
- match:先分析文档,再通过分析的文档进行查询
吴小凡 也会被查出来
两个字段类型
- text:会被分词器解析
- keyword:不会被分词器解析
创建索引,用mappings指明类型,并插入数据
PUT testdb
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"desc": {
"type": "keyword"
}
}
}
}
PUT testdb/_doc/1
{
"name": "赵深宸 name",
"desc": "致远 desc"
}
PUT testdb/_doc/2
{
"name": "赵深宸 name2",
"desc": "致远 desc2"
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
上述中 testdb 索引中,字段name在被查询时会被分析器进行分析后匹配查询。而属于keyword类型不会被分析器处理。
我们来验证一下:
- keyword
GET _analyze
{
"analyzer": "keyword",
"text": "赵深宸 name"
}
2
3
4
5
返回
{
"tokens" : [
{
"token" : "赵深宸 name",
"start_offset" : 0,
"end_offset" : 8,
"type" : "word",
"position" : 0
}
]
}
2
3
4
5
6
7
8
9
10
11
- standard
GET _analyze
{
"analyzer": "standard",
"text": "赵深宸 name"
}
2
3
4
5
返回
{
"tokens" : [
{
"token" : "赵",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "深",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "宸",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "name",
"start_offset" : 4,
"end_offset" : 8,
"type" : "<ALPHANUM>",
"position" : 3
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
查询测试下:
GET testdb/_search
{
"query": {
"match": {
"desc": "致远 desc"
}
}
}
2
3
4
5
6
7
8
结果:
只返回 一条数据,查询结果没有 “致远 desc2”
- 指定字段类型进行查询
GET stars/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name.keyword": "吴亦凡"
}
}
]
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
查找多个精确值
https://www.elastic.co/guide/cn/elasticsearch/guide/current/_finding_multiple_exact_values.html
# 高亮查询
- 默认高亮标签
GET stars/_search
{
"query": {
"match": {
"name": "吴亦凡"
}
},
"highlight": {
"fields": {
"name": {}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
返回
{
"took" : 160,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 2.9424872,
"hits" : [
{
"_index" : "stars",
"_type" : "_doc",
"_id" : "2",
"_score" : 2.9424872,
"_source" : {
"name" : "吴亦凡",
"age" : "29",
"desc" : "大碗宽面",
"tags" : [
"加拿大",
"电鳗",
"说唱",
"嘻哈"
]
},
"highlight" : {
"name" : [
"<em>吴</em><em>亦</em><em>凡</em>"
]
}
}
]
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
- 自定义高亮标签
GET stars/_search
{
"query": {
"match": {
"name": "吴亦凡"
}
},
"highlight": {
"pre_tags": "<p class='key' style='color:red'>",
"post_tags": "</p>",
"fields": {
"name": {}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
结果:
"highlight" : {
"name" : [
"<p class='key' style='color:red'>吴</p><p class='key' style='color:red'>亦</p><p class='key' style='color:red'>凡</p>"
]
}
"highlight" : {
"name" : [
"<p class='key' style='color:red'>吴</p>小<p class='key' style='color:red'>凡</p>"
]
}
2
3
4
5
6
7
8
9
10
11
# 聚合查询
我们知道SQL中有group by,在ES中它叫Aggregation,即聚合运算。
用之前导入索引的数据进行测试
# 简单聚合
比如我们希望计算出每个州的统计数量, 使用aggs关键字对state字段聚合,被聚合的字段无需对分词统计,所以使用state.keyword对整个字段统计
group_by_state 为取的名字,根据自己需求取名
GET /bank/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword"
}
}
}
}
2
3
4
5
6
7
8
9
10
11
返回:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1000,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"group_by_state" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 743,
"buckets" : [
{
"key" : "TX",
"doc_count" : 30
},
{
"key" : "MD",
"doc_count" : 28
},
{
"key" : "ID",
"doc_count" : 27
},
{
"key" : "AL",
"doc_count" : 25
},
{
"key" : "ME",
"doc_count" : 25
},
{
"key" : "TN",
"doc_count" : 25
},
{
"key" : "WY",
"doc_count" : 25
},
{
"key" : "DC",
"doc_count" : 24
},
{
"key" : "MA",
"doc_count" : 24
},
{
"key" : "ND",
"doc_count" : 24
}
]
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
因为无需返回条件的具体数据, 所以设置size=0,返回hits为空。
doc_count表示bucket中每个州的数据条数。
# 嵌套聚合
比如承接上个例子, 计算每个州的平均结余。涉及到的就是在对state分组的基础上,嵌套计算avg(balance):
GET /bank/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword"
},
"aggs": {
"average_balance": {
"avg": {
"field": "balance"
}
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
返回:
{
"took" : 49,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1000,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"group_by_state" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 743,
"buckets" : [
{
"key" : "TX",
"doc_count" : 30,
"average_balance" : {
"value" : 26073.3
}
},
{
"key" : "MD",
"doc_count" : 28,
"average_balance" : {
"value" : 26161.535714285714
}
},
{
"key" : "ID",
"doc_count" : 27,
"average_balance" : {
"value" : 24368.777777777777
}
},
{
"key" : "AL",
"doc_count" : 25,
"average_balance" : {
"value" : 25739.56
}
},
{
"key" : "ME",
"doc_count" : 25,
"average_balance" : {
"value" : 21663.0
}
},
{
"key" : "TN",
"doc_count" : 25,
"average_balance" : {
"value" : 28365.4
}
},
{
"key" : "WY",
"doc_count" : 25,
"average_balance" : {
"value" : 21731.52
}
},
{
"key" : "DC",
"doc_count" : 24,
"average_balance" : {
"value" : 23180.583333333332
}
},
{
"key" : "MA",
"doc_count" : 24,
"average_balance" : {
"value" : 29600.333333333332
}
},
{
"key" : "ND",
"doc_count" : 24,
"average_balance" : {
"value" : 26577.333333333332
}
}
]
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
# 对聚合结果排序
可以通过在aggs中对嵌套聚合的结果进行排序
比如承接上个例子, 对嵌套计算出的avg(balance),这里是average_balance,进行排序
GET /bank/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword",
"order": {
"average_balance": "desc"
}
},
"aggs": {
"average_balance": {
"avg": {
"field": "balance"
}
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21