 ES - 索引和文档的基本操作
ES - 索引和文档的基本操作
# 索引简单操作
# 创建索引
Postman 进行测试
由于我的 ElasticSearch 部署到在公关上,且有账号和密码
所以地址为:http://用户名:密码@url
本地则为:http://127.0.0.1:9200
- 创建索引:http://127.0.0.1:9200/shopping
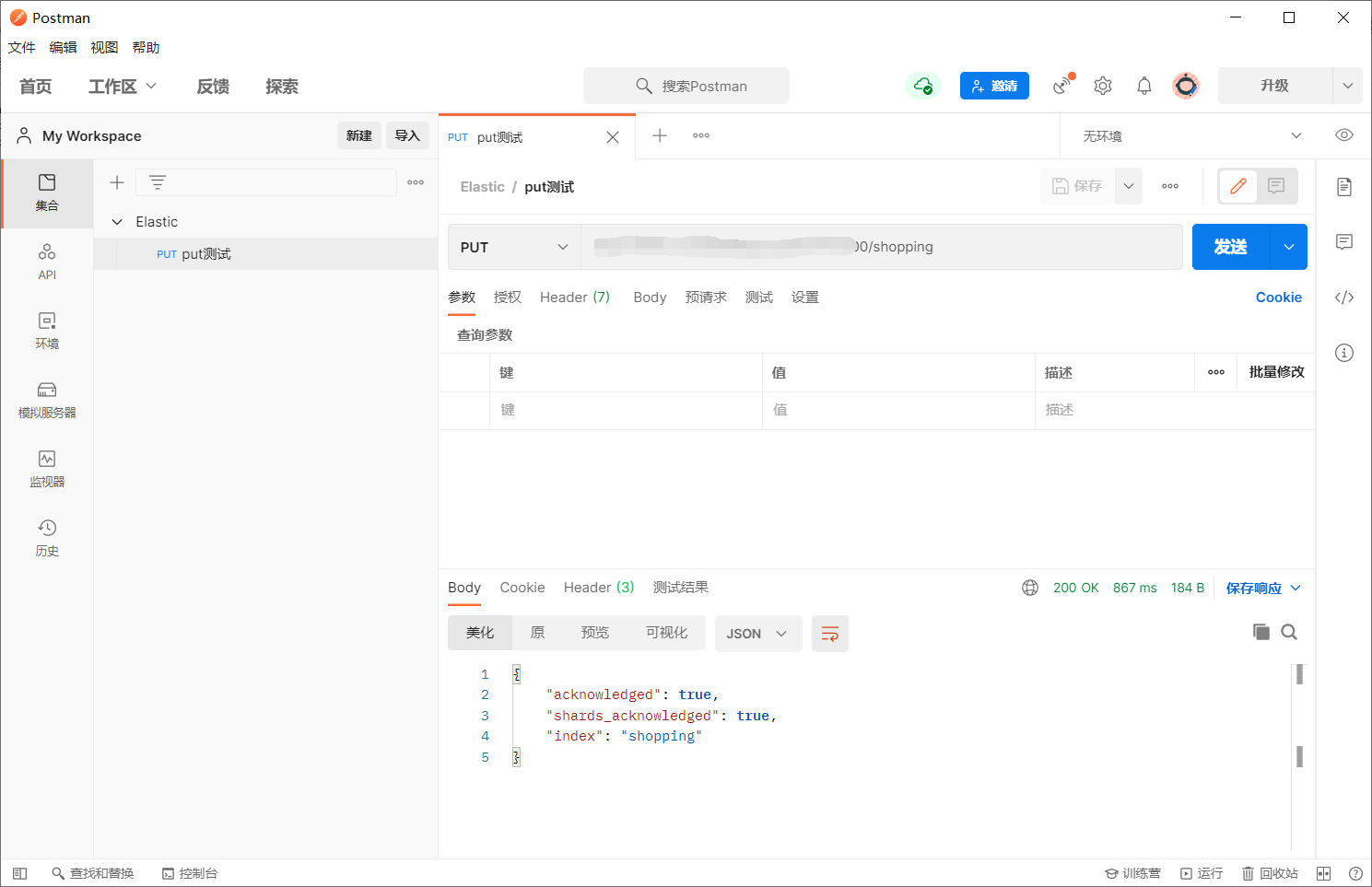
{
//响应结果
"acknowledged": true,
//分片结果
"shards_acknowledged": true,
//索引名称
"index": "shopping"
}
2
3
4
5
6
7
8
注意:创建索引库的分片数默认 1 片,在 7.0.0 之前的 Elasticsearch 版本中,默认 5 片
Kibana的 dev tool 进行测试
如果重复添加索引,会返回错误信息
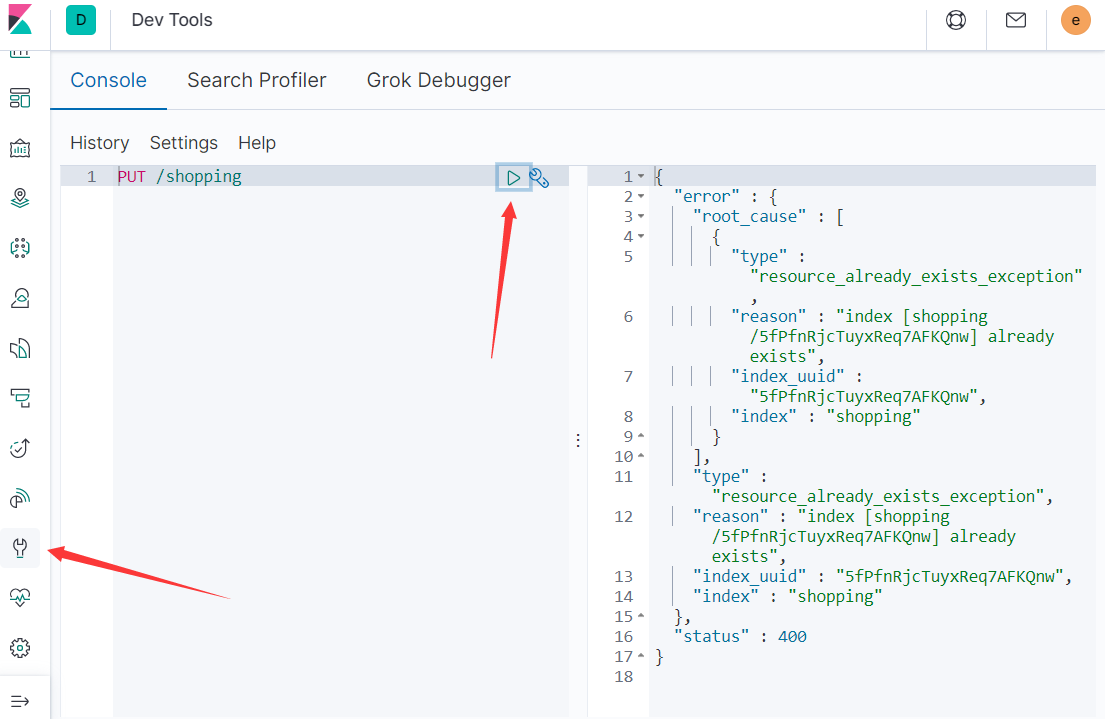
为了方便测试,后续使用kibana的dev tool来进行学习测试
# 查看和删除索引
查看所有索引
GET /_cat/indices?v

这里请求路径中的_cat 表示查看的意思,indices 表示索引,所以整体含义就是查看当前 ES 服务器中的所有索引
| 表头 | 含义 |
|---|---|
| health | 当前服务器健康状态: green(集群完整);yellow(单点正常、集群不完整);red(单点不正常) |
| status | 索引打开、关闭状态 |
| index | 索引名 |
| uuid | 索引统一编号 |
| pri | 主分片数量 |
| rep | 副本数量 |
| docs.count | 可用文档数量 |
| docs.deleted | 文档删除状态(逻辑删除) |
| store.size | 主分片和副分片整体占空间大小 |
| pri.store.size | 主分片占空间大小 |
查看单个索引
GET /shopping
查看索引向 ES 服务器发送的请求路径和创建索引是一致的。但是 HTTP 方法不一致。这里可以体会一下 RESTful 的意义,
响应结果:
{
"shopping" : {//【索引名】
"aliases" : { },//【别名】
"mappings" : { },//"【映射】
"settings" : {
"index" : {
"creation_date" : "1624201817578",//【创建时间】
"number_of_shards" : "1",//【主分片数量】
"number_of_replicas" : "1",//【副分片数量】
"uuid" : "5fPfnRjcTuyxReq7AFKQnw",//【唯一标识】
"version" : {
"created" : "7060199"//【版本】】
},
"provided_name" : "shopping"
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
删除索引
- DELETE /索引
DELETE /shopping
{
"acknowledged" : true
}
2
3
4
# 批量索引文档_bulk
ES 还提供了批量操作,比如这里我们可以使用批量操作来插入一些数据,供我们在后面学习使用。
使用批量来批处理文档操作比单独提交请求要快得多,因为它减少了网络往返。
下载测试数据
https://download.elastic.co/demos/kibana/gettingstarted/accounts.zip
数据的格式如下
{
"account_number": 0,
"balance": 16623,
"firstname": "Bradshaw",
"lastname": "Mckenzie",
"age": 29,
"gender": "F",
"address": "244 Columbus Place",
"employer": "Euron",
"email": "[email protected]",
"city": "Hobucken",
"state": "CO"
}
2
3
4
5
6
7
8
9
10
11
12
13
例如把文件复制到 ES 目录的 data
docker:
docker cp /home/accounts.json 06c5914709a5:/usr/share/elasticsearch/data/
然后执行
curl -H "Content-Type: application/json" -XPOST "localhost:9200/bank/_bulk?pretty&refresh" --data-binary @accounts.json
如果在其他目录,例如 /opt//accounts.json
curl -H "Content-Type: application/json" -XPOST "localhost:9200/bank/_bulk?pretty&refresh" --data-binary "@/opt/accounts.json"
或者我们可以直接插入数据:
注意格式json和text均不可,要去kibana里Dev Tools
POST http://localhost:9200/bank/_bulk
两行为一个整体,index代表索引,也就是保存操作,下面一行为保存的数据
{"index":{"_id":"1"}}
{"name":"a"}
{"index":{"_id":"2"}}
{"name":"b"}
2
3
4
- 语法格式:
action:执行的动作,新增,修改,删除等
metadata:要操作的数据,比如id是多少
{action:{metadata}}\n
{request body }\n
{action:{metadata}}\n
{request body }\n
2
3
4
5
这里的批量操作,当发生某一条执行发生失败时,其他的数据仍然能够接着执行,也就是说彼此之间是独立的。
bulk API 以此按顺序执行所有的 action(动作)。如果一个单个的动作因任何原因而失败, 它将继续处理它后面剩余的动作。当 bulk API 返回时,它将提供每个动作的状态(与发送 的顺序相同),所以您可以检查是否一个指定的动作是不是失败了。
实例:
对于整个索引执行批量操作(需在kibana里Dev Tools)
当没指定任何索引时,就是对整个作批量操作
POST /_bulk {"delete":{"_index":"website","_type":"blog","_id":"123"}} {"create":{"_index":"website","_type":"blog","_id":"123"}} {"title":"my first blog post"} {"index":{"_index":"website","_type":"blog"}} {"title":"my second blog post"} {"update":{"_index":"website","_type":"blog","_id":"123"}} {"doc":{"title":"my updated blog post"}}1
2
3
4
5
6
7
8
# 文档基本操作
# 添加数据 PUT
- 添加用户1
PUT /stars/_doc/1
{
"name": "蔡徐坤",
"age": "22",
"desc": "鸡你太美",
"tags": ["唱","跳","rap","篮球"]
}
2
3
4
5
6
7
得到响应如下:
{
"_index" : "stars",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
2
3
4
5
6
7
8
9
10
11
12
13
14
- 添加用户2
PUT /stars/_doc/2
{
"name": "吴亦凡",
"age": "29",
"desc": "大碗宽面",
"tags": ["加拿大","电鳗","说唱","嘻哈"]
}
2
3
4
5
6
7
- 添加用户3
PUT /stars/_doc/3
{
"name": "吴小凡",
"age": "10",
"desc": "一个吴小凡",
"tags": ["帅哥","干饭"]
}
2
3
4
5
6
7
# 查询数据 GET
- 简单查询
GET /stars/_doc/1
{
"_index" : "stars",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "蔡徐坤",
"age" : "22",
"desc" : "鸡你太美",
"tags" : [
"唱",
"跳",
"rap",
"篮球"
]
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
- 条件查询_search?q=
例如查询 name 是 赵深宸
GET /stars/_search?q=name:吴小凡
{
"took" : 996,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 2.5902672,
"hits" : [
{
"_index" : "stars",
"_type" : "_doc",
"_id" : "3",
"_score" : 2.5902672,
"_source" : {
"name" : "吴小凡",
"age" : "10",
"desc" : "一个吴小凡",
"tags" : [
"帅哥",
"干饭"
]
}
},
{
"_index" : "stars",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.3862942,
"_source" : {
"name" : "吴亦凡",
"age" : "29",
"desc" : "大碗宽面",
"tags" : [
"加拿大",
"电鳗",
"说唱",
"嘻哈"
]
}
}
]
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
- 查询所有
GET /stars/_search
{
"query": {
"match_all": {}
}
}
2
3
4
5
6
相关字段解释
took– Elasticsearch运行查询所花费的时间(以毫秒为单位)timed_out–搜索请求是否超时_shards- 搜索了多少个碎片,以及成功,失败或跳过了多少个碎片的细目分类。max_score– 找到的最相关文档的分数hits.total.value- 找到了多少个匹配的文档hits.sort- 文档的排序位置(不按相关性得分排序时)hits._score- 文档的相关性得分(使用match_all时不适用)
# 更新数据 POST
- post
POST /stars/_doc/1/_update
{
"doc": {
"name": "坤坤"
}
}
2
3
4
5
6
{
"_index" : "stars",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1
}
2
3
4
5
6
7
8
9
10
11
12
13
14
_version - 版本,也就是更新次数
result - 操作结果为更新
- put
也可覆盖数据来更新
PUT /stars/_doc/1
{
"name": "蔡坤坤",
"age": "22",
"desc": "鸡你太美",
"tags": ["唱","跳","rap","篮球"]
}
2
3
4
5
6
7
# 删除数据 DELETE
删除一个文档不会立即从磁盘上移除,它只是被标记成已删除(逻辑删除)。
- 根据 ID 删除数据
DELETE /stars/_doc/1
- 条件删除文档
一般删除数据都是根据文档的唯一性标识进行删除,实际操作时,也可以根据条件对多条数据进行删除
例如:查询 age 为 22 的
POST /stars/_delete_by_query
{
"query":{
"match":{
"age": 22
}
}
}
2
3
4
5
6
7
8
# 索引的自动创建
添加数据时,没有索引会自动创建索引和字段
PUT /customer/_doc/1
{
"name": "John Doe"
}
2
3
4
我们可以查看下这个索引的 mapping => GET /customer/_mapping
{
"customer" : {
"mappings" : {
"properties" : {
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
那么如果我们需要对这个建立索引的过程做更多的控制:比如想要确保这个索引有数量适中的主分片,并且在我们索引任何数据之前,分析器和映射已经被建立好。那么就会引入两点:第一个禁止自动创建索引,第二个是手动创建索引。
- 禁止自动创建索引
可以通过在 config/elasticsearch.yml 的每个节点下添加下面的配置:
action.auto_create_index: false
# 索引的格式
在请求体里面传入设置或类型映射,如下所示:
PUT /my_index
{
"settings": { ... any settings ... },
"mappings": {
"properties": { ... any properties ... }
}
}
2
3
4
5
6
7
- settings: 用来设置分片,副本等配置信息
- mappings: 字段映射,类型等
- properties: 由于type在后续版本中会被Deprecated, 所以无需被type嵌套
# 索引管理操作
https://www.pdai.tech/md/db/nosql-es/elasticsearch-x-index-mapping.html#索引管理操作 (opens new window)